1 、绪论、疾病的分布
2 、描述性研究和疾病检测
3 、病例对照研究
4 、队列研究
5 、实验流行病学
6 、筛检
7 、病因与因果推断
一、绪论
掌握:
1. 流行病学的概念、特点和用途。
2. 疾病频率测定的常用指标及其意义和计算方法。
3. 疾病分布的概念和类型。
熟悉:
1. 描述疾病流行强度的指标。
2. 疾病三间分布的描述方法及分布特征形式。
了解:
1. 流行病学用途及面临的挑战。
2. 流行病学与其它学科的关系。
3. 流行病学发展的方向。
(一)流行病学的定义
是研究人群中疾病和健康状况的分布及其影响因素,并研究防制疾病及促进健康的策略和措施的科学。
(二)流行病学定义的内涵
研究对象 : 人群
研究内容:全面的疾病和健康状态,包括疾病、伤害、健康三个层次
研究任务:a.描述疾病、伤害和健康状态等现象在人群中的分布,揭示现象;
b.从分析现象入手找出疾病、伤害和健康状态等现象流行与分布的规律和原因
c.利用前两阶段的结果制定预防措施和策略 研究目的:预防、控制和消灭疾病,促进健康
(三)流行病学的发展史
l 流行病学思想的萌芽
最早的关于自然环境与健康和疾病关系的记载——希波克拉底《空气、水、土壤》。“流行 ”一词也在此出现
中国——《黄帝内经》;意大利威尼斯——最早的检疫
1662 年,英国流行病先驱John Graunt 首次利用统计学方法对死亡数据进行死亡分布及规律性研究,
l 流行病学学科形成
1747 年,英国 James Lind——VitC 缺乏-坏血病——开创了流行病学临床试验的先河 1796 年,英国Edward Jenner——接种牛痘预防天花——开创了主动免疫的先河
1807-1883,英国William Farr —— 首创人口和死亡的常规资料收集,提出许多流行病学的重要概念 现代流行病学的奠基人之一,公共卫生运动的领导者之一
1848-1854,英国John Snow——伦敦宽街霍乱使用暴发标点地图法——流行病学现场调查、分析与控制的经典实例 1850 年,全世界第一个流行病学学会“英国伦敦流行病学学会 ”成立,标志着流行病学学科的形成
l 流行病学学科发展
20 世纪 40 年代至今,现代流行病学时期
20 世纪 40 年代至 50 年代,疾病谱由流行病转向慢性病,
英国 Richard Doll & Austin Bradford Hill——吸烟与肺癌——开创了生活方式的研究领域
开辟了慢性病病因学研究的新天地
20 世纪 60 年代至 80 年代:
1979 年,Sackett——35 种偏倚
1985 年,Miettinen——将偏倚分为比较、选择、信息偏倚三类
Jerome Cornfield 在美国的 Framinghan 心血管研究中建立第一个多变量模型——logistics 教材和著作:
1970 年,MacMahon——《流行病学原理和方法》 1976 年,Lifiwnfeld——《流行病学基础》
1986 年,Rothman——《现代流行病学》
1983 年,Last——《流行病学词典》——确定了现代流行病学定义 20 世纪 90 年代
流行病学与其他学科交叉融合,1993 年——Schulte——《分子流行病学——原理与实践》
l 中国流行病学发展
20 世纪 50 年代,全国流行病学高师班标志着我国流行病学学科体系的初步形成。 1953 年,我国初步建立了卫生防疫体系;1972 年苏德隆教授——Koch 病因推断
(四)流行病学基本原理
①疾病分布原理:描述疾病与健康状态的特征,从人群特征、时间特征和地区特征 3 方面
②病因论与病因推断:所有能引起某疾病发生概率增高的因素都可以称为是该病的病因
③疾病预防控制:根据疾病发生、发展和健康状况的变化规律,疾病预防控制可以采取三级预防策略: 第一级预防:病因预防
第二级预防:早发现、早诊断、早治疗(慢性非传染病)
早发现、早诊断、早报告、早隔离、早治疗(传染病) 第三级预防:合理治疗疾病并防止伤残、延长生命
(五)流行病学的思维方式
宏观的思维、对比的思维、概率统计的思维、发展的思维
(六)流行病学研究方法
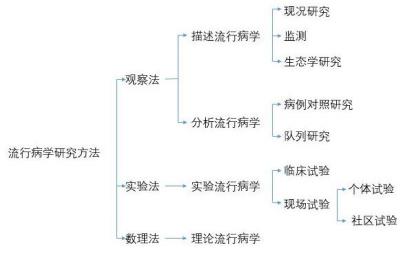
(七)流行病学的应用
①描述疾病及健康状况的分布
②研究疾病的病因和危险因素
③揭示疾病的自然史
④预防疾病和促进健康
⑤评价疾病防治措施的效果
(八)流行病学的进展
①传染病与非传染病并重
②临床流行病学与循证医学
③宏观研究与微观研究相结合
④加强大型人群队列建设与病因研究
⑤重视医学大数据在流行病学中的应用
二、疾病的分布
(一)疾病分布
概念:指疾病在不同人群、不同时间、不同地区的发生频率和分布特征,简称为“三间分布 ”,即人间、时间、空 间分布。
意义:探索疾病流行规律及其影响因素,为建立病因假设及探索病因提供线索,为临床和卫生服务需求提供重要信 息,也为制定疾病的防制策略和措施提供科学依据。
(二)描述疾病分布的常用测量指标
一、率和比的概念
l 率(rate)
表示在一定的条件下某现象实际发生的例数与可能发生该现象的总例数之比, 用以说明单位时间内某现象发生的频率或强度。
l 比(ratio)
也称【相对比】,是表示两个数相除所得的值,说明两者的相对水平,常用倍数或百分数表示。
l 构成比(proportion)
表示事物内部各个组成部分占的比重,常以百分数表示。
构成比是反映事物中各组成部分的比重或分布,并不能反映事物某一部分发生的频率或强度。
二、发病指标
l 发病率(incidence rate)
指一定时期内、特定人群中某病新病例出现的频率。
意义:用来衡量某时期某地区人群发生某种疾病危险性大小的指标 用途: 1. 常用来描述疾病分布
2. 探讨发病因素
3. 提出病因假设
4. 评价防制措施的效果
分子:为新发病例数,以发病时间为依据。在观察期间一个人如果多次发生同种疾病,应分别计算为多个新发病例 分母:为同期暴露人口数,指观察人群中可能会发生观察疾病的人。一般使用年平均人口数来替代暴露人口数
l 罹患率(attack rate)
测量某人群某病新发病例的频率指标,与发病率不同的是用衡量小范围人群中在较短时间内的发病率
用途:描述食物中毒、职业中毒及传染病的暴发流行
与发病率的区别:罹患率用于衡量小范围、短时间内新发病例的频率
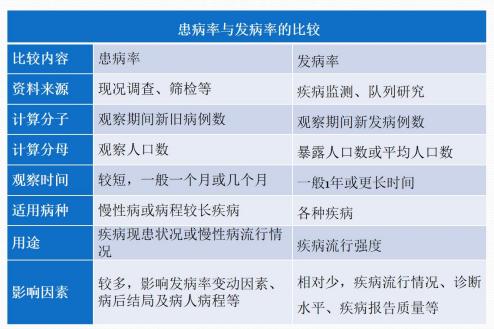
l 患病率(prevalence)
亦称【现患率】或【流行率】
是指在特定时间内,某病现患(新、旧)病例数与同期观察人数之比。
患病率是横断面调差得出的疾病频率,故调查时间不宜过长,一般应在 1 个月至数个月内完成,最好不超过 1 年。
①分类:时点患病率、期间患病率
②与发病率区别:1. 分子不同;2. 患病率是衡量疾病的存在或流行情况;发病率是衡量疾病的出现情况
③影响患病率的因素 升高:
病程延长、未治愈者的寿命延长、发病率增高、病例迁入、健康者迁出、易感者迁入、增大水平提高、报告率提高 降低:
病程缩短、病死率高、发病率下降、健康者迁入、病例迁出、治愈率提高 患病率与发病率的关系:
当某地某病的发病率和该病的病程在相当长时间内保持稳定时:患病率=发病率×病程 用途:
1. 横断面研究的常用指标,用于慢性病,反映疾病负担
2.为医疗设施规划、医疗质量评价和医疗经费的投入提供科学依据
3. 研究疾病流行因素、防制效果
l 感染率
用途:研究具有较多隐性感染的传染病和寄生虫病的感染状况及防治工作的效果,估计某病的流行态势 l 续发率
也称【二代发病率】,指在一定观察期内某种传染病在易感接触者中二代病例出现的百分率 用途:1. 分析比较不同传染病传染力的大小
2. 分析流行因素,评价防制措施的效果
三、发病指标
l 死亡率(mortality rate)
指某人群在一定期间内死于所有原因的人数在该人群中所占的比例,又称【粗死亡率】
应用:死亡率是反映一个人群总死亡水平的指标,用于衡量某一时期,某一地区人群死亡危险性的大小。 可作为某些病死率高的恶性肿瘤的病因探讨指标。
分母必须是与分子相对应的人口,比如分子是计算某地 50 岁以上女性的口腔癌死亡专率, 分母应该为该地 50 岁以上女性人口数
l 病死率(fatality rate)
表示一定期间内,患某病的全部病人中因该病而死亡的比例。
病死率= 一定期间内因某病死亡人数× 100%
同期患某病的人数
用途:
(1)表示确诊疾病的死亡概率,常用于急性病
(2)衡量疾病对人生命威胁的程度
(3)反映医疗水平 影响因素:
(1)疾病严重程度
(2)医疗水平
(3)诊断水平
(4)病原体毒力变化
(5)就诊率(医院)
l 生存率(survival rate)
是指患某种疾病的人(或接受某种治疗措施的病人)经 n 年的随访,到随访结束时仍存活的病例数占观察病例 总数的比例。
用途:生存率反映了疾病对生命的危害程度,常用于评价某些慢性病如癌症、心血管病等疾病的远期疗效。
(三)疾病的流行强度
定义:指在一定时期内,某病在某地区某人群中发病率的变化及其病例间的联系程度。 l 散发
含义:指某病在某地区人群中呈历年的一般发病率水平,病例在人群中散在发生或零星出现,病例之间无明显联系。 判断:与当地前 3 年该病的发病率水平相比较,未明显超过既往一般水平即可称散发。
应用:散发用于描述较大范围(如区、县以上)地区疾病流行强度。 举例:
1.该病在当地常年流行,居民通过隐性感染获得了一定的免疫力/因预防接种使人群维持一定的免疫水平,如麻疹等。 2. 以隐性感染为主的传染病,可出现散发,如脊髓灰质炎等。
3.传播机制不容易实现的传染病,如炭疽等
4.潜伏期长的传染病也容易出现散发,如麻风 l 暴发
定义:是指在一个局部地区或集体单位的人群中,短时间内突然出现许多临床症状相似的病人。
原因:暴发往往是通过共同的传播途径感染或由共同的传染源引起,集体食堂的食物中毒、托幼机构的麻疹暴发等。 l 流行
含义:某地区某病发病率显著超过历年的散发发病率水平。 判断:与疾病散发相比而言的。
举例:本章案例 18-1 中戊型肝炎的疫情性质为流行。
l 大流行
定义:某病发病率显著超过该病历年发病率水平,疾病蔓延迅速,涉及地区广,在短期内跨越省界、国界甚至洲界 形成世界性流行。
例如:2003 年的 SARS 、2019 新冠状病毒肺炎。
(四)疾病的分布形式
1 、流行病学研究中重要的内容,
2 、是描述性研究的核心,
3 、是分析性研究的基础,
4 、是制定疾病防制策略和措施的依据
n 疾病的时间分布
(1)短期波动
又称【暴发】或【时点流行】,是指在一个集体或固定人群中,短时间内某病发病数突然增多的现象。 短期:主要是指在该病的最长潜伏期内。
原因:许多人接触同一致病因子或共同的传播途径所致。常见于食物中毒、急性传染病、化学毒物中毒等。 (2)季节性
疾病的频率在一定季节内升高的现象。3 种表现形式:
①季节性升高 ②严格的季节性 ③无季节性(书上没有)
(3)周期性
指有些疾病每隔一个相当规律的时间间隔发生一次流行的现象。
多见于呼吸道传染病——流行性感冒、流行性脑脊髓膜炎、麻疹等疾病。
其发生取决于易感者积累的速度、病原体变异的速度、传染病的传播是否容易实现
(4)长期趋势
又称为【长期变异】,
指在一个相当长的时间内(通常几年或几十年) ,疾病的发病率、死亡率、临床表现及病原体型别同时发生显著变化。 n 疾病的地区分布
常用的描述疾病地区分布的方法:
①地区划分方法:
按行政区域划分:如国家、省、市、县等。
按自然环境特征来划分:山区、平原、湖泊、森林或气温、降雨量、海拔高度等。
②地区分布图的绘制③率的比较
(1)疾病在国家间和国家内的分布 分布差异的原因:
自然地理因素;媒介昆虫与储存宿主的分布;居民生活饮食习惯;宗教信仰;经济文化水平;医疗卫生水平等。
(2)疾病的城乡分布 分布差异的原因:
生活条件、卫生状况、人口密度、交通条件、工业水平、动植物的分布等。 城市——呼吸道传染疾病;农村——消化道疾病
(3)疾病的地方性
由于自然环境和社会因素的影响而使一些疾病常在某一地区呈现发病率增高或只在该地区存在,这种状况称为 地方性。
①统计地方性: 由社会因素导致。伤寒、痢疾
②自然地方性:受自然环境影响。(地方病) 疟疾、血吸虫病、丝虫病
③自然疫源性:病原体能独立地在自然界的野生动物中绵延繁殖,只在一定条件下传染给人。
(4)判断地方性疾病的依据
①该地区的居民发病率均高,并可随年龄的增长而上升;
②在其他地区居住的相似人群中,该病的发病率均低,甚至不发病;
③外来的健康人,到达当地一定时间后可能发病,其发病率和当地居民相似;
④迁出该地区的居民,该病发病率下降,患者症状减轻或呈自愈趋向;
⑤当地对该病易感的动物可能发生类似疾病。
n 疾病的人群分布
年龄、性别、职业、种族和民族、社会阶层、婚姻和家庭、行为 (1)年龄
1 、研究疾病年龄分布的目的
①根据年龄分布特征可以确定重点保护对象和高危人群,为今后有针对性地开展防制工作提供依据。
②分析年龄分布差异可以为病因研究提供线索,有助于深入探索致病因素。
③根据年龄分布的动态趋势,有助于观察人群免疫状况的变化,确定预防接种对象。
2 、疾病年龄分布差异的原因
①不同人群免疫水平存在差异。
②不同人群因生活方式、心理行为等差异导致暴露于致病因素的机会不同。
③有效的预防接种改变了某些疾病的固有发病特征。
3 、疾病年龄分布的分析方法
①横断面分析
定义:主要通过描述不同年龄组的发病率、患病率和死亡率来分析潜伏期较短的急性疾病的年龄分布,多用于传染 病的分析。不适用于慢性病,不能正确显示致病因素与年龄的关系。
②出生队列分析
定义:将同一时期出生的人划归为一组称为出生队列,对在不同年龄阶段某病的发病率、死亡率等进行的分析,以 了解发病或死亡随年龄而变化的趋势和不同出生队列的暴露特点对发病或死亡的影响。
应用:可明确显示致病因子与年龄的关系。适用于分析潜伏期长的慢性病的年龄分布。
n 疾病的人群、地区、时间分布的综合描述
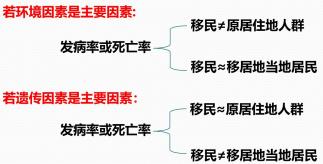
(1)移民流行病学
含义:通过比较移民人群、移居地当地人群和原居住地人群的某病发病率和死亡率差异,分析该病的发生与遗传因 素和环境因素的关系。对疾病在不同地区、不同人群、不同时间进行的综合描述,其主要目的是区分遗传因 素和环境因素的大小。
目的:分析疾病病因中,环境因素与遗传因素的作用大小。
(2)移民流行病学研究的原则
三、描述性研究
掌握:
1.横断面研究、普查、抽样调查的概念。
2.抽样的基本方法及决定抽样调查的样本大小的主要因素。 熟悉:
1.普查、抽样调查目的及优缺点 ; 2.现况研究的具体实施与偏倚;
了解:
1.描述性研究的类型。
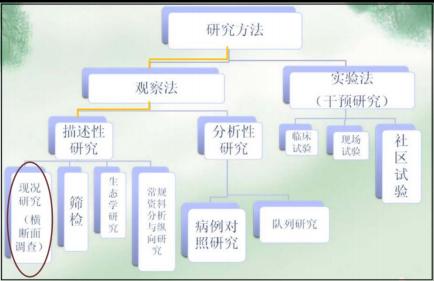
(一)描述性研究的概念
又称描述性流行病学,是流行病学研究中最基本的类型,是指利用已有的资料或对专门调查的资料(包括实验 室检查结果),按不同地区、不同时间和不同人群特征进行归纳整理后,把疾病或健康状态或暴露因素的分布特征 展现出来,并在此基础上形成观点或假设的一种方法。
(二)描述性研究的类型
现况研究、生态学研究(群体水平)、筛检、病例报告(罕见病)、病例系列分析、个案研究、暴发调查、随 访研究、历史资料分析等
(三)现况研究的概念
又称横断面研究。在特定时间内调查某一人群中有关变量与疾病或健康状况关系的一种方法。其目的是描述目 前疾病或健康状况的分布及某因素与疾病的关联。
收集的资料既不是过去的记录,也不是随访的资料,而是调查时点或者时期内所得到的疾病、健康和其他有关 资料。因此,现况调查又称为对疾病的现患率/患病率研究
现况研究多适用于对病程较长、患病率较高的疾病进行研究。
(四)现况研究的目的
1、描述特定时间疾病/健康状况的三间分布 中国 15 个城市儿童血铅水平及影响因素
2、发现病因线索
低出生体重儿现况调查 母亲被动吸烟 3、适用于疾病的二级预防
早期发现、早期诊断、早期治疗
4、评价疾病的防治效果或者健康促进措施效果
0-14 岁儿童乙肝疫苗接种情况及免疫指标调查
5、疾病或健康状态的监测
6、为研究和决策提供基础性资料
(五)现况调查的分类
l 研究特点
1、一般不设对照组
2、在确定因果联系时受到限制
3、可以提示因果联系
l 普查
概念:指为了了解某种健康状况或疾病的患病率,在特定时间对特定范围内人群中每一位成员进调查或检查的方法。
目的:是疾病的早期发现和诊断 适用条件:
(1)有足够的人力、物力和设备投入病例诊断和治疗。
(2)调查目的明确、项目简单,被调查者容易接受。
(3)有高度统一指挥和组织体系。
(4)疾病患病率较高,或暴露率较高。
(5)检验方法不复杂,试验的灵敏度和特异度较高。
(6)符合医学伦理学的要求。 优点:
(1)能发现人群中的全部病例,做到早发现、早诊断疾病,并可以普及医学卫生知识;
(2)确定对象比较简单
(3)获得资料全面
(4)没有抽样误差
(5)工作范围集中,容易动员,节省时间 缺点:
(1)工作量大,耗费大
(2)组织工作复杂
(3)范围大时内容调查有限,不适用于患病率很低和现场诊断技术比较复杂的疾病
(4)容易重复和遗漏
(5)因为工作量大,调查质量不易控制
l 抽样调查
概念:在特定时点、特定范围内的某人群总体中,按照一定的方法抽取一部分有代表性的个体组成样本进行调查分 析,并用其结果来推论该人群中某种疾病或某种特征。
目的: 以样本统计量估计总体参数,描述疾病或健康状况在特定时间、特定范围内人群及其影响因素的分布特征 可用于描述疾病或健康状态的三间分布、衡量人群总体健康水平、考核防治效果。
基本原理:
(1)抽样遵循随机化原则。
(2)遵循医学伦理学原则。
(3)样本量要适当。
(4)必须要在研究的总体中进行抽样。
(5)不同的抽样方法,抽样误差不同。
(6)要根据调查目的,进行科学设计选择合理的抽样方法。 优点:
(1)节省人力、物力、时间;
(2)随机抽取,有代表性;
(3)调查精确度提高。 缺点:
(1)有抽样误差
(2)不适用变异较大的资料和需要普查普治的情况及患病率低的疾病
(3)设计实施复杂,重复和遗漏不易发现
(4)样本含量方可实现对抽样误差的控制。若样本扩大到接近总体的 75%时,不如直接普查。
(六)抽样方法的类型
l 单纯随机抽样
l 系统抽样/机械抽样/等距抽样
l 整群抽样:随机选择若干个集体作为观察单位,如居民小区、班级、连队、乡
l 分层抽样:指按照某种特征或者特性(年龄、性别、住址)。将总体分为不同的层,层内进行抽
l 两级/多级抽样
(七)现况调查的实施步骤
①明确调查目的
②确定调查对象
③确定调查类型和方法
④选择适当的抽样方法和样本含量
⑤统计分析数据
(八)研究样本含量的大小考虑因素
①预计所调查疾病患病率:如现患率低,则样本量要大;反之,样本可小些。
②调查要求达到的精确度:调查要求的精确度越高,即允许误差(d)越小,样本量就越大;反之亦然。 ③显著性水平 ( α ) : α越小,样本量越大, α通常取 0.05 或 0.01。
(九)现况调差中常见的偏倚与控制
l 选择偏倚
①无应答偏倚:若应答率< 80%,代表性欠佳
②选择性偏倚:没有严格按照随机化原则
③幸存者偏倚
l 信息偏倚
①报告偏倚:回答不准确从而引起的偏倚。
②回忆偏倚:调查对象对暴露史/疾病史回忆不清。
③调查员偏倚:调查员有意识地深入调查某些人的某些特征,而不重视或马虎对待其他人的这些特征。
④测量偏倚: 由于测量工具、检验方法不正确、化验技术操作不规范等导致的系统误差。
l 控制偏倚
①严格遵照抽样方法的要求,确保抽样过程的随机化原则。
②明确入选标准及结果判断标准。
③正确选择调查工具和检测方法。
④正确校正测量仪器。
⑤统一培训调查员。
⑥进行预调查。
⑦调查后抽样重测。
⑧注意选择正确的统计分析方法,辨析混杂因素及其影响。
(十)现况调查的优缺点 l 优点
①现况调查可以弥补常规报告资料的不足,较短的时间内得到调查结果,花费不大,是最常用的流行病学调查方法。
②其次,现况调查是在收集资料完成之后,将样本按是否患病或是否暴露来分组比较,对照组来自自然形成的同期 同一群体,使结果具有可比性,可进行检验假设。
③现况调查往往采用问卷调查、采样检测手段收集研究资料,一次调查可同时观察多种因素,对多个因素同时分析。
l 缺点
①现况调查是对特定时点和特定范围的规定,因此调查时疾病与暴露因素一般同时存在,难以确定先因后果的时相 关系。
②其次,现况调查得到的是某一时点的是否患病的情况,故不能获得发病率资料。
四、公共卫生监测
掌握: 公共卫生监测的概念和基本要素。
熟悉: 公共卫生监测的目的和意义。
了解: 被动监测、主动监测的概念和内容。
(一)概述
公共卫生监测是公共卫生实践的重要组成部分。最早的监测针对疾病发生和死亡,故称疾病监测。
随着监测内容不断扩大,公共卫生监测不仅包括疾病(传染病和慢性非传染性疾病),还包括行为危险因素、 环境因素、出生缺陷、药物不良反应以及突发公共卫生事件等。
通过系统的公共卫生监测,获得重要的公共卫生信息,为制定和完善疾病预防控制及其他公共卫生应对策略和 措施提供科学依据。
(二)公共卫生监测的概念
是长期、连续、系统地收集人群中有关健康问题、卫生事件的资料,经过分析和解释后将信息及时反馈给有关 部门和人员,用以指导制定、实施和评价公共卫生干预措施与策略的过程。
(三)公共卫生监测的三个基本要素
①信息收集
长期、连续、系统地收集人群中疾病、健康状态或卫生问题的资料,发现其分布特征和变化趋势。 ②信息分析
对所收集的原始资料进行整理、分析和解释,将其转化为有价值的公共卫生信息。 ③信息反馈和利用
及时将信息反馈给有关部门和人员,利用这些信息及时制定、调整相关的策略和措施,并评价其效果。
(四)公共卫生监测的目的
1. 了解疾病/卫生事件模式,确定主要的公共卫生问题
2. 发现异常情况,查明原因,及时采取干预措施
3. 预测疾病/卫生事件流行,估计卫生服务需求
4. 确定疾病/卫生事件的危险因素和高危人群
5. 评价干预效果,制定科学有效的公共卫生策略和措施
(五)公共卫生监测的种类
l 疾病监测
(1)传染病监测 (2)非传染病的监测
①监测人群的基本情况
②监测传染病分布的动态变化
③监测人群传染病的易感性
④监测病原体的型别、毒力和耐药性情况;
⑤监测传染病的动物宿主,昆虫媒介及传染来源;
⑥评价防疫措施的效果;
⑦研究疾病病因学、流行因素和流行规律;
⑧预测疫情。
l 危险因素监测
l 症状监测
l 其他问题的监测:营养、环境等
(六)疾病监测的概念
也称流行病学监测,是指长期、连续和系统地收集疾病的动态分布及其影响因素的资料,经过分析将信息及时 上报和反馈,传达给所有应当知道的人, 以便及时采取干预措施并评价其效果。
疾病监测的最终目的是控制疾病。
(七)疾病监测的方法
①被动检测:常规法定管理传染病报告。
②主动检测:上级单位专门调查或要求下级单位严格按规定调查收集资料。
③哨点监测:流感监测系统
④无关联匿名监测:HIV 监测
⑤记录连接
⑥监测的直接指标与间接指标
⑦动态人群和静态人群——有无人口迁出入。
⑧保密制度
(八)疾病监测系统
1. 全国法定管理传染病报告系统
2. 全国疾病监测点监测系统
3. 以医院为基础的监测系统
4. 单病监测系统
(九)药物不良反应的概念
药物不良反应(ADR)是指合格药品在正常用法用量情况下,出现的与用药目的无关的或意外的对人体有害或意 外的反应。
(十)药物不良反应监测的概念
监测上市后药品的不良反应情况,是药物的再评价工作的一部分。其监测工作的主要内容是:
①收集药品不良反应信息,对药品不良反应的危害情况进行进一步的调查,及时向药品监督管理机构报告,并提出 相关的药品管理意见和措施;
②及时向药品生产经营企,医疗预防保健机构和患者反馈药品不良反应信息,保证患者用药安全。
(十一)药物不良反应监测的方法
常用的药物不良反应监测方法包括以下几种:
1. 自愿报告系统(spontaneous reporting system,SRS)
2. 义务性监测(mandatory or compulsory monitoring)
3. 重点医院监测(intensive hospital monitoring)
4. 重点药物监测(intensive medicines monitoring)
5. 速报制度(expedited reporting)
(十二)药物不良反应因果关系的评价
将药物不良反应因果关系分为肯定、很可能、可能、可能无关、待评价和无法评价六个等级 药物不良反应因果关系的判断主要考虑五个方面:
①开始用药的时间与不良反应出现的时间有无合理的先后关系?
②所出现的不良反应是否是该药品已知不良反应的类型?
③停药或减少药量后,反应是否减轻或消失?
④再次接触药品后是否再次出现相同的反应?
⑤出现的可疑不良反应是否可用并用药的作用、病人的临床状态或其他疗法的影响来解释?
五、病例对照研究
✓ 掌握:
1. 病例对照研究的定义、原理、特点、优点及局限性。
2. 病例对照研究中的资料整理与分析(成组资料和 1 ∶ 1 配比研究,OR 值)。
✓ 熟悉:
病例对照研究中的偏倚及控制。
✓ 了解:
病例对照研究方法的类型与实施
(一)病例对照研究的概念
是选定患有所研究疾病的人群作为病例组,未患有该病的人群作为对照组,分别调查上述两组所有对象既往对 某个(或某些)因素的暴露情况和暴露水平,并比较两组中暴露率或暴露比例的差异,以研究该疾病与这个(或这 些)因素关系的一种观察性研究方法。
(二)病例对照研究的基本原理
1、以确诊患某种特定疾病的病人作为病例;
2、以不患该病但具有可比性的个体作为对照;
3、通过询问、实验室检查或复查病史,搜集既往危险因素暴露史;
4、测量并比较两组各因素的暴露比例,经统计学检验该因素与疾病之间是否存在统计学关联;
5、在评估了各种偏倚对研究结果的影响之后,再借助病因推断技术,推断出某个或某些暴露因素是疾病的危险因 素,从而达到探索和检验疾病病因假说的目的。
(三)病例对照研究的特点
1、观察性研究;
2、研究对象分为病例组和对照组;研究对象是按是否有研究的结局分成病例组与对照组
3、由“果 ”溯“ 因 ”:病例对照研究是再结局(疾病事件)发生之后追溯可能原因的方法;
4、因果联系的论证强度相对较弱:病例对照研究不能观察到由因到果的发展过程,故因果联系的论证强度不及队 列研究。
(四)病例对照研究的用途
1、用于疾病病因或危险因素的研究: 特别适合于研究某些潜伏期较长及罕见的疾病;
2、用于健康相关事件影响因素的研究;
3、用于疾病预后因素的研究;
4、用于临床疗效影响因素的研究。
(五)病例对照研究的类型
l 非匹配的病例与对照(成组病例对照研究):
在设计所规定的目标病例和对照人群中,分别抽取一定量的研究对象,对照选择时可没有特殊规定。(两组人
数可相等也可不等)
优点:相对比较简单,对照容易选择,资料容易处理,适用于大样本的研究,或病例较多,容易获得时的研究
l 病例与对照匹配:
匹配或称配比,是指依据病例的某些特征选择对照,即对照在某些特定的因素上与病例保持一致。匹配的目的 是使病例与对照之间保持较好的可比性,排除某些因素对研究结果的干扰作用。
匹配因素:
必须为已知的或有充分理由怀疑的混杂因素(与暴露因素有关、与疾病有关、不是暴露与疾病因果链上的某一环节)。
(1)频数匹配(frequency matching):按照某个特征在病例组中出现的频率,选择对照组。 Eg:若病例组的男性占 65%,则对照组的男性也应为 65%
(2)个体匹配(individual matching):按照每个病例的某些特征选择与之匹配的对照。
1:1 匹配又称配对;1:2、1:3、1:R 匹配也行
l 匹配的作用
结果容易解释 ;提高研究效率 ;控制混杂因素
l 匹配的注意事项
匹配过头:把不必要的项目列入匹配,企图使病例与对照尽量一致,就可能徒然丢失信息,增加工作难度,结果反 而降低了研究效率。应当注意避免。
不能匹配的因素:研究因素与疾病因果链中的中间变量、暴露无关但疾病有关因素、暴露有关但疾病无关因素、欲 研究的因素。(不是混杂因素)
匹配设计较成组设计复杂、对照选择困难、资料处理复杂、容易丢失信息, 一般适用于:病例较少、成本较高、研究的投入较少。
l 衍生的几种主要研究类型
(1)巢式病例对照研究(nested case-control study)
(2)病例-队列研究(case-cohort study)
(3)病例-病例研究( case-case study)
(4)病例交叉研究( case crossover study)
(六)病例对照研究设计与实施的基本步骤
l 1、确定研究目的
l 2、确定研究类型
1、如果研究目的是广泛地探索疾病的危险因素,可以采用非匹配或频数匹配的病例对照研究方法;
2、如果研究的是罕见病,或所能得到的符合规定的病例数很少,则选择个体匹配。
3、以较小的样本量获得较高的检验效率。
1:R 的匹配方法,R 值越大,统计学效率越高,但是随着 R 值的增加,效率增加幅度越来越小,而工作量却显 著增大,因此,R 值一般不宜超过 4
l 3、确定研究因素
1、暴露因素可以多种多样,可以是宏观因素,如社会经济地位、生活方式等,也可以是微观的,如易感基因。
2、尽可能采取国际或国内统一的标准对每项研究因素的暴露与否或暴露水平做出明确而具体的规定, 以便交流和 比较。
3、测量指标尽量选用定量或半定量指标,也可按明确的标准进行定性测定。
l 4、确定研究对象(病例的选择)
1. 病例的定义: ①尽量采用国际通用或国内统一的诊断标准,以便于他人的工作比较;
②需要自订标准时,注意均衡诊断标准的假阳性率及假阴性率的高低,宽严适度。
2. 病例的类型:
①新发病例:是病例对照的首选的病例类型。
>优点:新发病例包括不同病情和预后的患者,代表性好,且病例资料容易获得, 准确可靠。
>缺点:是在一定范围或一定时间内较难得到预期的病例数,对于罕见疾病更是如此。应用现患病例则可能弥补上 述缺陷,在较小的范围或较短时间内得到足够的病例数
②现患病例:
患病时间较长,对暴露史回忆的可靠度要比新发病例差,难以区分暴露与疾病发生的先后顺序。因此,在应用现患 病例时,要尽量选择诊断时间距离进行调查的时间间隔较短的病例。
③死亡病例:
暴露信息主要由其家属提供,准确性较差,但对那些主要靠亲友提供资料的疾病如儿童白血病的研究,也不排除应 用死亡病例,只是在资料整理和分析时要充分考虑到可能的偏倚。
3. 病例的来源:
(1)从医院选择病例:即从一所或几所医院甚至某个地理区域内全部医院的住院或门诊确诊的病例中选择一个时 期内符合要求的连续病例。
>优点:可节省费用,病例具有比较合作,资料容易获得且比较完整、准确,较易实施等。
>缺点:医院的病例代表性差,会产生选择偏倚。特别是当病人选自专科医院时,往往带有一定的选择性,其结果 仅能反映该医院病人特点,而不是全人群该病病人的特点。
>解决:为了减少偏倚,病例应尽可能的选自不同地区、不同水平的综合医院。
(2) 以社区为基础选择病例: 以某一地区某一时期内某种疾病的全部病例或其中的一个随机样本作为研究对象。 如在社区人群进行普查或抽样调查时发现的病例,或进行社区疾病监测时发现的病例等,作为调查对象。
>优点:是病例的代表性好,对照的选择比较简单,不易产生选择偏倚。
>缺点:调查对象的依从性难以保证,调查的难度比较大,所以选择此类型的病例进行研究可行性较差。
l 4、确定研究对象(对照的选择)
1、选择对照的原则:
对照必须是以与病例相同的诊断标准认为不患所研究疾病的人。
对照应该能够代表产生病例的源人群,即对照的暴露分布应该与病例源人群的暴露分布一致。
2、对照的选择应满足以下 4 个条件:
①排除选择偏倚;
②缩小信息偏倚;
③缩小不清楚或不能很好测量的变量引起的残余混杂;
④在满足真实性要求和逻辑限制的前提下使统计把握度达到最大。
3、对照的来源:
(1)同一个或多个医疗机构中诊断的患其他疾病的人
(2)病例的邻居或同一居委会、住宅区内的健康人或非该病病人
(3)社会团体人群中的非该病病人或健康人
(4)社区人口中的非该病病人或健康人
(5)病例的配偶、同胞、亲戚、同学或同事等
4、分析:
第(1)种最常用
优点:是应答率高,合作性好,资料容易获得且质量较高。
缺点:代表性差,易发生选择偏倚。为了避免偏倚,应选择多个医院、多个科室、多病种的病人作对照。 第(4)种最接近全人群的无偏样本
即从一般人群中选择对照。如果病例是来源于人群,如来源于死亡报告、肿瘤登记、 疾病监测、普查或抽样调查
等的病例,则对照也应从人群中选择,以提供良好的可比性和代表性。 缺点:无应答率较高,不易实施,且费时、费钱。
第(2)和(5)用于匹配设计的对照
优点:是对照在很多方面与病例相一致,可比性较好。同胞作对照可平衡生长发育早期的环境因素和遗传因素的影 响;配偶作对照,可控制婚后环境因素的影响;选择邻居、同事作对照,可平衡居住环境、社会经济地位等的影响。 缺点:是在某些研究因素方面可能与病例有相同的暴露。
l 5、确定样本量
1、影响样本量的因素:
①研究因素在对照组或人群中的暴露率(P0);
②研究因素与疾病关联强度的估计值,即比值比(OR);
③希望达到的统计学检验假设的显著性水平,即第 Ⅰ类错误(假阳性)概率 ( α) , 一般取α=0.05;
④希望达到的统计学检验假设的效能或把握度(1-β) , β为第Ⅱ类错误(即假阴性)概率,一般取β=0.1。 > P0与其在病例组中的暴露率(P1)差值越大,所需的样本含量越小。
> P0保持不变时,相对危险度(RR)或比值比(OR)的估计值越远离 1,即研究因素与疾病的联系强度越大,所需 的样本含量越小。
> 如果希望犯第 Ⅰ类错误的概率α和第Ⅱ类错误的概率β越小,那么所需的样本含量越大。
l 6、资料的收集
(1)方式:访谈、信函、电话、档案、实验室检测、临床查体
(2)资料收集步骤
1. 培训调查员:按照设计方案及调查手册进行调查员培训;掌握调查要领、技术和注意事项。 2.小规模预调查:调查员培训合格后,进行小规模调查,发现问题进行修改、完善。
3.开展现场调查
>严格按照调查表及设计要求进行; >调查员之间必须统一方式、方法;
>病例与对照之间必须同一调查表、相同方法、方式; >每个调查员调查的病例与对照的比例基本相同
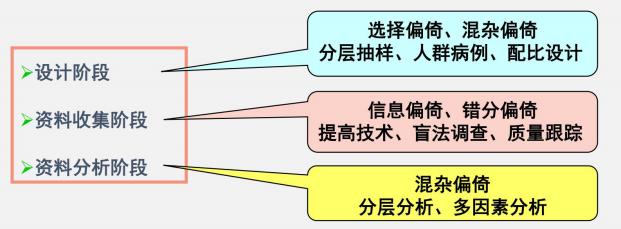
l 7、质量控制
分析研究的各个环节可能出现的问题及解决的方法,通常是针对三大偏倚采取的措施。
(七)资料整理与分析
l 资料的分析(重点)
(1)描述性统计
1、描述研究对象的一般特征:
如病例组和对照组中研究对象的人数、性别、年龄、职业、居住地、出生地、疾病类型等。 一般用均数和构成比表示。频数匹配时,还应描述病例组和对照组中匹配因素。
2、均衡性检验:
是指检验病例组与对照组在研究因素以外的其他基本特征方面是否相似或相同。目的是为了检验两组间的可比 性。(常用 t 检验、方差分析、卡方检验)。
(2)统计性推断
n 比值比(odds ratio, OR):病例对照研究中表示疾病与暴露之间关联强度的指标。

➢病例对照研究(某些衍生类型除外)不能计算发病率,所以也不能计算相对危险度,只能用OR 作为反映关联强 度的指标。
➢OR 值的意义与相对危险度(RR)相同,指暴露者发生某种疾病的危险性是非暴露者的多少倍。
OR>1:表示暴露与疾病呈正关联,数值愈大,说明被研究的暴露因素充当危险因素的可能性就愈大; OR<1:表示暴露与疾病呈负关联,数值愈小,说明该因素充当保护因素的可能性愈大;
OR=1:表示暴露与疾病无关联。
➢ 当满足下面两个条件时,OR 值就很接近甚至等于 RR 值 ✓ 所研究疾病的发病率(死亡率)很低;
✓ 病例对照研究中对照组的代表性好,即其暴露率能代表源人群。
1、成组资料
是病例对照研究资料分析的基本形式
(1)将数据整理成四格表
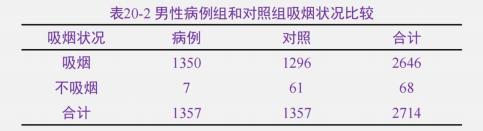
(2)利用卡方检验,检验病例组和对照组的暴露率有无显著性的统计学差异
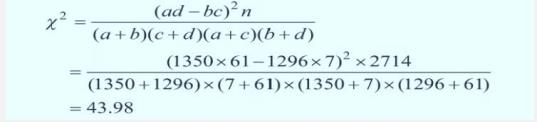
已知 χ2
结论为拒绝无效假设,即病例组与对照组吸烟的暴露率的差异有统计学意义,且病例组吸烟暴露率大于对照组的吸 烟暴露率。
(3)计算暴露与疾病的关联强度
OR=ad/bc
OR=9.08;表明吸烟者患肺癌的风险是不吸烟者的 9.08 倍。
(4)计算 OR 的可信区间
使用 Miettnen 卡方值法:
OR 值的 95%CI 的意义:
说明有 95%的可能性计算得出的可信区间包含总体 OR,根据可信区间是否包含 1 来推断研究因素与疾病关联强度的 可靠性。不包含 1 就是有意义的。
2、匹配资料
(1)将数据整理成四格表
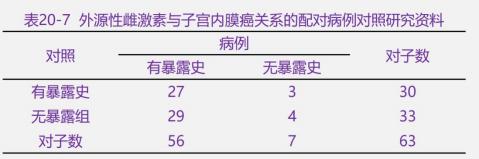
(2)利用卡方检验,检验病例组和对照组的暴露率有无显著性的统计学差异

本例计算得, χ2
结论为拒绝无效假设,说明外源性雌激素与子宫内膜癌之间存在关联。
(3)计算暴露与疾病的关联强度 OR=c/b=29/3=9.67
(4)计算 OR 的可信区间
使用 Miettnen 卡方值法:
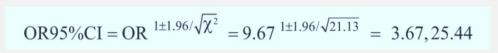
OR 的 95%CI 为 3.67~25.44
结果说明外源性雌激素的使用是子宫内膜癌发生的可能危险因素,且使用外源性雌激素患子宫内膜癌的风险是 未使用外源性雌激素的 9.67 倍。
(八)病例对照研究的优缺点
1. 优点
(1)特别适用于罕见病、潜伏期长疾病的病因研究,有时往往是罕见病病因研究的唯一选择。
(2)相对更节省人力、物力、财力和时间,并且较易于组织实施。
(3)可以同时研究多个暴露与某种疾病的联系,特别适合于探索性病因研究。
(4)应用范围广,不仅应用于病因的探讨,而且广泛应用于其他健康事件的原因分析。
2. 缺点
(1)不适于研究人群中暴露比例很低的因素。
(2)选择研究对象时,难以避免选择偏倚。
(3)获取既往信息时,难以避免回忆偏倚。
(4)暴露与疾病的时间先后常难以判断,论证因果关系的能力没有队列研究强。
(5)不能测定暴露组和非暴露组疾病的发病率,不能直接分析 RR,只能用OR 来估计 RR。
(九)病例对照研究可能存在的偏倚
l 选择偏倚:
1、入院率偏倚,又称伯克森偏倚
是指利用医院门诊患者或住院患者作为病例与对照时,常因各种疾病的入院机会不同而使研究结果偏离了真实值。
2、现患病例-新发病例偏倚,又称奈曼偏倚
病例对照研究中,选择的病例常常是现患病例,不包括那些死亡病例、轻型病例、不典型病例以及病程短的病例
3、检出症候偏倚,又称暴露偏倚
是指某因素与某疾病在病因学上虽无关联,但由于该因素的存在而引起疾病的某些症状或体征出现,促使患者及 早就医,从而使具有该暴露因素的人群该病的早期病例检出率高,以致得出该因素与疾病有关联的错误结论。
l 信息偏倚:
1、回忆偏倚;
2、调查偏倚。
l 混杂偏倚(考):
在病例对照研究中由于存在一个或多个既与研究因素有关,又与研究疾病有关的混杂因素的影响,掩盖或夸大 了研究因素与疾病之间真正关联,由此产生的偏倚称为混杂偏倚(confounding bias)。
控制混杂的方法
(1)研究设计阶段:随机化、限制、匹配
(2)资料分析阶段:分层分析、多因素分析
思考题
1. 病例对照研究的基本原理是什么?
2. 如何开展一项病例对照研究?
3. 病例对照研究的优缺点有哪些?
六、队列研究
掌握:
(1) 队列研究的定义、特点;
(2) 队列研究的暴露因素与疾病关联强度的意义及计算方法。 熟悉:
(1) 队列研究的种类与实施;
(2) 队列研究中的偏倚及控制;
(3) 队列研究的用途与优缺点。 了解:
(1)队列研究资料的收集与整理方法;
(2)队列研究样本含量的估计方法
(一)概念
队列:表示有共同经历或共同暴露特征的一群人,例如:出生队列、吸烟队列 暴露:指研究对象接触过某种特征的因素或具有某种特征和行为
增加疾病发病危险的因素,即有害因素 降低疾病危险的因素,即保护因素。
队列研究:研究对象是加入研究时未患所研究疾病的一群人,根据是否暴露于所研究的病因或暴露程度而划分为不 同组别(队列),如暴露组和非暴露组,随访观察不同组别结局,从而判定暴露因素与发病有无因果关 联及关联强度的一种观察性研究方法。
一次研究可有多个结局
(二)队列研究的特点
1. 观察法
2. 设立对照
3. 观察方向由“ 因 ”及“果 ” ,先有暴露再有疾病,符合时间顺序
4. 能确证暴露与疾病的关系
(三)队列研究的用途或目的
1 、检验病因假设
2 、评价预防效果
3 、研究疾病发生史
(四)队列研究的类型
1、前瞻性队列研究
优点:可以直接获得暴露与结局的第一手资料,因而信息准确,不易产生信息偏倚。
缺点:但因需长时间随访,费时、费力,在应用的广度方面受到了限制。
2、回顾性队列研究
优点:虽然收集暴露资料和判断结局在同时完成,但是前瞻性的。
缺点:该方法的资料收集和分析可在较短时间内完成,若有完整的历史记录,可达到事半功倍的效果。
3、双向性队列研究
(五)队列研究设计
一、确定研究目的
二、确定研究因素
队列研究的暴露因素常在描述性研究或病例对照研究基础上选择,进一步证实暴露因素的致病或保护作用。对 暴露因素应尽可能给予定量。
三、选择研究对象
代表性好:年龄、性别等。
在研究开始时未见所研究的结局,并在研究过程中都有可能发展成为结局。 l 暴露组的选择
①职业人群:研究某种职业接触或其他相关因素对疾病或健康的影响,通常选择职业暴露人群做暴露组。
②特殊暴露人群:对某因素有高暴露水平的人群。
例如放疗或化疗的患者;经历地震人群研究地震对健康的长期影响等。
③一般人群:在社区人群中选择有暴露者作为研究对象。例如吸烟、超体重、有负性事件的人群。
④有组织的团体:是指有组织单位的人群。是一般人群的特殊形式。 由于前瞻性队列研究的主要偏倚是失访偏倚, 为了减少这种偏倚,选择有组织的人群便于随访,易于联系,应答率高。
l 非暴露组的对照
①内对照:
暴露组选择③④相对应的对照。以普通人群或有组织人群中的一部分无暴露/暴露水平低的人员作对照。 Eg:弗明汉研究中,30-62 岁普通居民为研究对象,吸烟者作为暴露组,非吸烟者作为对照组。
优点是暴露与对照人群来自同一总体,代表性和可比性好,选取对照较省事,也可以了解总体人群的发病率。 ②外对照:
当暴露人群①②时,需在该人群之外选取基本情况与暴露人群类似者作为对照。
Eg:研究石棉接触与肺癌的关系时,可选择工作条件、工作方式接近、但不接触是吗的工人做对照;
研究职业接触放射线与白血病的关系,选择放射科医生做暴露人群,其他科室医生做对照。 优点是容易观察到暴露的效应,缺点是两组可比性容易出现问题。
③总人口对照:
对应于暴露人群为①②的一种对照,可以看作是外对照的一种特殊形式。也可以看作没有对照。
利用暴露人群所在地的整个地区现成的相关疾病发病或死亡率作为对照。省时省力,但暴露组与对照组的可比 性容易存在问题。此外,全人群中也包括了暴露组。
常用于特殊暴露的职业人群的研究。
④多重对照
从上述对照的形式中选择两组或两组以上对照,以加强结果的说服力。
四、确定样本量
l 影响样本量大小的因素
1. 非暴露人群或全人群中被研究疾病的发病率(P0); 越接近 50%,所需要研究的人数越少,
2. 暴露人群中被研究疾病的发病率 (P1);
3. 显著水平 α 值;越小,需要的样本数越多
4. 检验效能(1- β) ; 同样β越小,把握度越高,需要样本量则越大

五、确定研究结局
判定结局的标准:国际或国内统一标准。
六、随访与质量控制
1 、确定随访期
2 、统一测量方法
常用的测量方法:
(1)调查询问
(2)查阅有关资料
(3)定期医学检查
(4)监测环境因素
制定严格具体的测量质量控制措施,减少测量误差。
(六)队列研究常用数据描述指标
l 累积发病率(CI)
CI=观察期内的发病人数/观察开始时的人数
适用条件:人口稳定、样本量大、观察时间短 l 发病密度(ID)
又称人年发病率,是一定时期内的平均发病率 ID=观察期内的发病人数/观察人时
适用条件:人口不稳定、样本含量大、观察时间长 人时:观察人数×观察时间(最常用年)
l 标化死亡率(SMR)
在职业流行病学研究中较常用,是以全人口的发病(死亡)率作为标准,计算出该观察人群的理论发病(死亡) 人数,即预期发病(死亡)人数。
SMR=研究人群中实际死亡人数(O)/按标准人口计算的理论死亡人数(E) 适用条件:人群数量小,不便/不能计算死亡率
意义:标化比是一个率的替代指标,相当于以该观察人群为暴露组,以一般人群为对照组形式,计算出来的发病或 死亡的比值。
SMR=1 研究人群某病死亡危险=标准人群
SMR>1 研究人群某病死亡危险>标准人群,是标准人群的SMR 倍 SMR<1 研究人群某病死亡危险<标准人群
(七)关联强度
l 相对危险度(RR)
RR 也叫危险比(risk ratio)或率比(rate ratio),
RR=暴露组发病率(或死亡率)/非暴露组发病率(或死亡率)=Ie/I0 说明暴露与疾病关联的强度及其在病因学上意义大小的指标。
RR 的意义:
RR=1 暴露因素对疾病不产生影响
RR>1 暴露因素是疾病的危险因素,RR 值越大,因果联系的强度越大 RR<1 暴露因素是疾病的保护因素,RR 值越小,保护作用越强。
l 归因危险度(AR)
又称为率差(rate difference)是暴露组发病率/死亡率与非暴露组发病率/死亡率之差。
AR = 暴露组发病率(或死亡率) – 非暴露组发病率(或死亡率) = Ie – I0 说明暴露者单纯由于暴露而增加的发病概率。
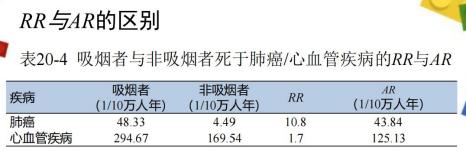
RR值,吸烟者与非吸烟者相比,其死于肺癌的风险高于死于冠心病,说明吸烟与肺癌的病因联系较强; 意义:表明暴露者和非暴露者比较增加相应疾病危险性的倍数,吸烟对肺癌的病因学意义较大。
AR值,因为心血管疾病的死亡率远高于肺癌,所以吸烟人群若原本不吸烟就可减少 136.46/10 万人年的心血管疾病 死亡,但只能减少 45.43/10 万人年的肺癌死亡率。所以 AR更具有公共卫生学意义。
意义:表明暴露因素消除,可减少的发病数量,戒烟对心血管疾病的预防作用较大,即公共卫生意义较大。
l 归因危险度百分比(AR%)
又称病因分值 EF,是指暴露人群因某因素暴露所致的某病发病或死亡占该人群该病全部发病或死亡的百分比。 计算公式为:
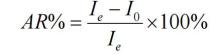
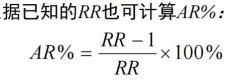
意义:AR%的某病患者与曾经暴露因素有关
l 人群归因危险度(PAR)
PAR = 全人群发病率(或死亡率)➖ 非暴露组发病率(或死亡率)= It – I0
说明人群由于暴露于某一危险因子而增加的发病率。 暴露因素消除后所减少的疾病数量。 意义:全人群中某暴露因素的患者比正常人群相比其某病的发生率增加了 PAR
l 人群归因危险度百分比(PAR%)
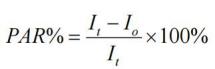
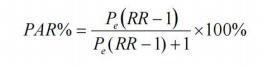
Pe 是总人群对某因素的暴露率。
意义: 若全人群不接触某暴露因素,则将减少 PAR%的某病死亡率(发生率)。
全人群中,由某致病因素导致的某病占所有患病的 PAR% 全人群中,有 PAR%的某病由暴露因素引起的
(八)队列研究的优缺点
l 优点:
①研究结局是亲自观察获得,一般较可靠。
②是由“ 因 ”至“果 ”观察,符合因果关系的时间顺序,论证因果关系的能力较强。
③可计算暴露组和非暴露组的发病率,能直接估计暴露因素与发病的关联强度。
④一次调查可观察多种结局。 l 缺点:
①不适用于研究人群中发病率很低的疾病
②观察时间长不易获得完整的资料
③耗费的人力、物力和时间较多。
④设计的要求高,实施复杂。
⑤在随访过程中,未知变量引入人群,或人群中已知变量的变化等都可使结局受到影响,使分析复杂化。
⑥每次只能研究一个或一组暴露因素。
(九)队列研究可能存在的偏倚以及如何控制
l 选择偏倚
定义:研究人群在一些重要因素方面与一般人群或待研究的总体人群存在差异,而导致研究结果的偏倚。 控制:预防为主,抽样方法正确,严格按规定标准选择对象
l 失访偏倚
定义: 由于研究对象因迁移、外出、死于非终点疾病或拒绝继续参加观察而退出队列所引起的偏倚。 控制:①设计-选择便于随访的人群;在计算的研究样本的基础上扩大 10%
②实施-加强对随访员的管理;制定随访计划和监测措施;期中分析
③整理资料-对于有缺项或漏项的对象进行补查
l 信息偏倚
定义:在获取暴露、结局或其他信息时所出现的系统误差或偏差
控制:提高临床诊断技术、明确各项标准;选择精确稳定的测量方法;事前调准仪器;严格实验操作规程 同等对待每个研究对象;培训调查员,提高技巧,统一标准
l 混杂偏倚
定义:与所研究因素和结果均有联系的第三因素在暴露组与对照组的分布不均衡,混淆了研究因素和结果间的真实 联系。
控制:①设计阶段—限制研究对象,匹配 ②分析阶段–分层分析、标准化或多因素分析
七、实验性研究
•掌握 流行病学实验的基本特点,了解流行病学实验的主要类型。
•熟悉 流行病学实验的设计和实施:包括研究对象的选择原则、实验现场的确定、样本量的估计、随机化分组、 对照的设立及盲法的应用。
•熟悉 流行病学实验的优缺点,了解应注意的问题 。
(一)实验性研究的概念
【流行病学实验性研究、实验流行病学、流行病学实验】
将来自同一总体的研究人群随机分为实验组和对照组,研究者对实验组人群施加某种干预措施后,随访并比较 两组人群的发病(死亡)情况或健康状况有无差别及差别大小,从而判断干预措施效果的一种前瞻性、实验性研究方 法。
通过比较给予干预措施后的实验组人群与对照组人群的结局,来考核干预措施有效性和安全性的一种前瞻性研 究方法。
(二)实验性研究的基本特点:前瞻、干预、随机、对照
①干预在前,效应在后,属于前瞻性研究
②采用随机方法把研究对象分配到实验组和对照组
③研究对象均来自同一总体,其基本特征、 自然暴露因素、预后因素相似,对照组和实验组均衡可比
④在实验组和对照组分别采用干预措施和对照措施
(三)实验性研究的分类
l 临床试验(RCT): 以病人个体为对象,是在医院或其他医疗照顾环境下进行的试验,评价新药、新器械、新 治疗方法
l 现场试验又称干预试验,按照现场试验中接受干预的基本单位不同,评价健康教育、生活方式改变、疫苗 可分为:
①社区试验:是以未患病的人群为研究对象,以社区为实施单元,试验组给予某预防措施,对照组不给予 该预防措施,然后随访两组人群疾病的发生情况,评价措施的效果。 (CIP)
②个体试验:将未患所研究疾病的人群随机分为两组,以个体为施加试验措施的基本单位。每位分配到试验
组的个体均给予试验措施,对照组不给予该措施,后观察两组人群结局的发生情况,评价措施的效果。
(四)随机对照临床试验的概念
随机对照临床试验又称随机对照试验( RCT)、随机对照并行试验或同期随机对照试验。
是将临床病人随机分为试验组与对照组,试验组给予某临床干预措施,对照组不给予该措施,通过比较各组效 应的差别判断临床干预措施效果的一种前瞻性研究。
是典型的按照实验法的4 个原则设计的研究类型
(五)药物临床试验的设计和实施步骤
一、明确研究问题
l 原则:研究问题或题目的构建——PICO 模型
病人或人群(即问题)——Patients/Population 干预措施——Intervention
对照措施——Control 结局——Outcome
二、确定实验现场
①相对稳定、足够的数量
②较高、稳定的发病率
③疫苗:近期未发生该病流行
④较好的医疗卫生条件
⑤领导重视、群众配合 三、选择研究对象和分组
l 原则:
①选择对干预措施有效的人群
②选择预期发病率较高的人群
③选择干预对其无害的人群
④选择能将实验坚持到底、依从性好的人群
⑤选择代表性好、容易随访的人群
l 随机分组
✓ 单纯随机 随机数字法
✓ 区组随机 先分成例数相等的区组,区组中再随机
✓ 分层随机 对预后有明显影响的因素作为分层变量,将研究对象分层后再做随机分组。eg.性别、年龄 ✓ 整群随机 以群体为单位
分组隐匿:专人产生随机分组序列,此人不参与纳入观察对象,并将分组方案对所有参与研究的人员保密,包括研 究人员和受试者。
四、设立对照组
若不设立对照组,则可能会出现
1. 不能预知的结局 2. 霍桑效应 3. 安慰剂效应 4. 潜在的未知因素的影响 5. 向均数回归 6. 干预因素
l 设立对照方式
①空白对照 ②安慰剂对照 ③标准对照 ④不同给药剂量、不同疗程、不同给药途经相互对照
⑤自身前后 ⑥交叉 五、盲法实施
单盲、双盲、三盲
六、确定结局变量、测量方法和观察期限
①确定结局变量:预期观察的结果事件
如:发病或死亡,分子标志的变化,知识和行为的改变
②确定测量方法: 问卷调查,实验室检测
③确定观察期限:依据试验目的
临床试验短、社区试验长;传染病短、慢性病长 七、收集资料和随访
八、资料整理和分析
l 整理:退出(随机分组后)
不合格:不符合纳入标准,一次也没有接受干预或没有任何数据者不依从。 失访:一般不得超过 10%。
l 资料的分析
意向治疗分析:依从者分析:接受治疗分析:
l 评价指标
(1)治疗效果的指标 (2)预防效果的指标
(六)实验性研究的优缺点
l 优点
①随机分组,能够较好地控制偏倚和混杂
②为前瞻性研究,因果论证强度高(两组同步,外来因素的干扰同时起作用,结果准确)
③有助于了解疾病的自然史
④获得一种干预与多种结局的关系 l 缺点
①难以保证有好的依从性
②难获得一个随机的无偏样本
③容易失访
④费用常较观察性研究高 容易涉及伦理道德问题
八、筛检
掌握:
1.筛检试验的定义、原则,评价指标及其计算方法。 2.联合试验的类型、意义。
熟悉:
1.筛检的原理、意义及应用条件。
2.筛检的策略。 了解:
1.筛检各项指标间的相互关系。
(一)筛检的概念
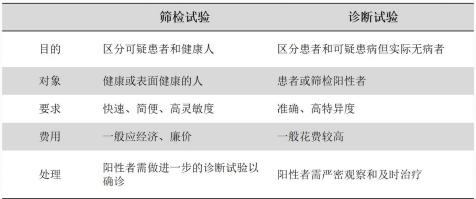
是运用快速、简便的试验、检查或其他方法,将健康人群中那些可能有病或缺陷、但表面健康的个体,同那些 可能无病者鉴别开来。所用的手段或方法称为筛检试验。
它是从健康人群中早期发现可疑病人的一种措施,不是对疾病做出诊断。
完整的疾病防止过程,第一步是筛检,第二步是诊断试验,第三步是治疗。
(二)筛检的分类
(1)按照筛检对象的范围划分:
①整群筛检; ②选择性筛检(又称高危人群筛检, 目标筛检)
(2)按照筛检项目的数量划分:
①单项筛检; ②多项筛检
(3)按照筛检目的划分:
①治疗性筛检;②预防性筛检
(4)按照筛检的组织方式划分:
①主动性筛检;②机会性筛检
(三)筛检的实施原则
①所筛检疾病应是该地区现阶段一个重大的公共卫生问题;
②对被筛检的疾病有进一步确诊、治疗或预防的方法与条件;
③所筛检疾病或状态的自然史明确,有足够长的潜伏期或临床前期以满足实施筛检;
④有合适的筛检技术;
⑤应考虑整个筛检、诊断、治疗的成本与收益问题。
(四)诊断试验的概念
指应用各种检查、试验或方法,进一步把患者与可疑患病但实际无病者区分开来,即识别出真正的患者。
(五)筛检试验与诊断试验的区别
(六)筛检的设计与实施
n 金标准的确定
n 研究对象的选择
总体原则:研究对象应能代表筛检或诊断试验可能应用的目标人群。对照可选未患所研究疾病的其他病例,也可选 用健康人。
在选择研究对象时应注意遵循随机化的原则
n 样本量的确定
(1)影响样本量大小的因素
1、待评价试验的灵敏度和特异度
用于疾病筛检的试验要求灵敏度高;
用于疾病临床诊断的试验要求特异度高。
2、检验水准α
一般定为 0.05, α值越小,所需样本量越大。
3、容许误差 δ
一般定为 0.05 或 0.10, δ值越小,样本量越大; δ值越大,样本量越小。
(2)样本量大小的计算
1、当灵敏度和特异度在 20% ~ 80% 区间变化时
2、当待评价的试验其灵敏度或特异度小于 20% 或大于 80% 时,
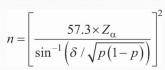
n 确定试验的指标与界值
(1)指标类型:主观、客观、半客观
客观指标的真实性和可靠性最好,主观指标的质量最差,在进行筛检和诊断试验指标选择时应尽可能选 择客观指标。
(2)确定界值原则
①对于预后差,漏诊后果严重,而早期诊断、治疗可获得很好的治疗效果的疾病,应选择灵敏度高的判定标准。
②当假阳性与假阴性同等重要时,选择患者与正常人分布的交界线处作为试验界值,即灵敏度和特异度均高的位置, 或正确诊断指数最大处。
③若疾病后续的诊疗方法不理想,如进一步确诊试验烦琐、费用高,
或疾病预后不严重但误诊一个正常人为患者时后果严重,对受试对象的心理、生理和经济上造成严重的影响, 应选择特异度高的判定标准。
(3)确定试验界值的方法
①正态分布法:
当试验的指标为定量指标并且呈正态分布时,确定正常和异常的临界值一般采用“均数 ± 1.96 倍标准差 ”的 方法,即 95% 的测量值在正常范围内,两端各 2.5% 为异常。
如果试验的测量值只有过高或过低为异常时,其单侧 5% 是异常的,则其单侧正常值范围用“均数 + 1.64 倍 标准差 ”或“均数 – 1.64 倍标准差 ”表示。
②百分位数法:
当试验的指标为偏态分布或分布类型不明确时,可用百分位数法确定临界值,即将观察值从小到大排列后,计 数累计次序。以第 2.5 ~ 97.5 百分位数表示双侧正常值范围, 以第 5 或 95 百分位数界定单侧正常值。
③ROC 曲线法:
【受试者工作特征曲线】,其优点是简单、直观、可视化,并能直接反映出灵敏度与特异度的关系。 纵坐标——真阳性率(灵敏度)
横坐标——假阳性率(1-特异度)
离坐标轴左上角最近的坐标点,可以同时满足试验的灵敏度和特异度相对最优,即为最佳诊断界值 ROC 曲线与坐标轴围成的 ROC 曲线下面积(AUC)也可以反映筛检或诊断试验的准确性。
ROC 曲线下面积取值范围一般为 0.5 ~ 1 。越大越接近 1 ,诊断准确度越高
④根据实际情况人为确定界值:
根据大量临床观察某些致病因素对健康损害的阈值,并结合健康人群和患者的测量值的分布资料,权衡漏诊和 误诊的比例与利弊后, 由专家讨论后制订正常与异常的分界值。
(七)筛检的常见偏倚
①领先时间偏倚
领先时间偏倚是指由于筛检的时间和临床诊断时间之差,被解释为由于筛检所延长的生存时间。 实际上是由于筛检导致的诊断时间提前所致的偏倚。
在进行筛检试验的评价时,比较筛检出的患者及医院就诊患者预后的生存期、病死率、治愈率等时,就可能因 为领先时间偏倚而使结果偏离真实情况。
②病程长短偏倚
疾病被检出的可能性和疾病的进展速度有关。
病程短的疾病被筛检出的可能性低于病程长的疾病。
如果筛检组中疾病进展缓慢的患者占较大比例,可能观察到筛检组较未筛检组生存概率更高或生存时间更长。 此时,筛检的效果被高估,即病程长短偏倚。
③过度诊断偏倚
由于筛检发现了过多的早期病例从而增加了后续诊断和治疗的负担,这种现象称为过度诊断。
某些不会进展的疾病如良性甲状腺肿瘤由于筛检而被发现、确诊患病,并被计入患者总体之中,导致经筛检发 现的患者有较多的生存者或较长的生存期,从而高估了筛检的效果,即产生了过度诊断偏倚。
过度诊断偏倚也是病程长短偏倚的一种极端形式。
④志愿者偏倚
志愿者偏倚的产生是由参与筛检者与不参加试验者可能在某些特征上不同而造成的。志愿者偏倚本质上属于选 择偏倚。
(八)筛检的评价
3 方面:真实性 + 可靠性 + 收益
n 真实性的评价(竖着算)
【准确性】或【效度】,是指试验所获得的测量值与真实值相符合的程度。常指金标准诊断得到的结果。 评价试验真实性的指标主要包括灵敏度、特异度、假阳性率、假阴性率、似然比及约登指数等。
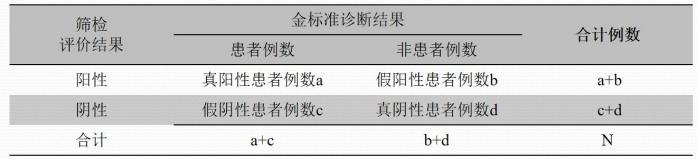
①灵敏度(Se)
【真阳性率】是指某项筛检或诊断试验将实际患病者正确判断为阳性的概率。理想的试验灵敏度应为 100%。
②特异度(Sp)
【真阴性率】,是指某项筛检或诊断试验将实际的非患病者正确地判断为阴性的概率。理想的试验特异度应为 100%。
③假阳性率(FPR)
【误诊率】,即某项筛检或诊断试验将实际无病者误判为阳性的概率。理想的试验假阳性率应为 0。
④假阴性率(FNR)
【漏诊率】,即某项筛检或诊断试验将真实的患者误判为阴性的概率。理想的试验假阴性率应为 0。
⑤约登指数(YI)
【正确诊断指数】,是指灵敏度与特异度之和减去 1。
约登指数 =(灵敏度 + 特异度)-1=1-(假阳性率 + 假阴性率)
意义:该指数表示某项试验识别真正患者与非患者的总能力。约登指数的取值范围为 0 ~ 1。 指数越大,则该试验的真实性越高。
⑥似然比(LR)
为病例组中得出某一试验结果的概率与对照组中得出这一概率的比值,说明患者中出现该结果的机会是非患者 的多少倍。
1 、阳性似然比(+LR)
意义:反映了患者中该试验出现阳性结果的概率是非患者的多少倍。 比值越大,试验结果阳性时其为真阳性的概率越大。
2. 阴性似然比(-LR)
意义:反映了患者中该试验出现阴性结果的概率是非患者的多少倍。 该比值越小,试验结果阴性时为真阴性的概率越大。
n 可靠性的评价(竖着算)
【信度】、【精确度】、【可重复性】,
是指在相同条件下筛检对同一研究对象重复检测时获得相同结果的稳定程度。值得注意的是,可靠性的评价与 金标准诊断是否患病的结果无关。
①变异系数(CV)
如果试验检测的指标为定量指标,可用变异系数来表示可靠性。 即( 测定值均数的标准差/测定值均数) ×100%。
变异系数越小,则试验可靠性越好。
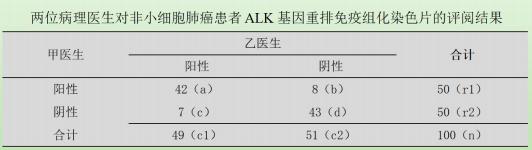
②符合率
【一致率】,是同一批研究对象两次诊断结果均为阳性/均为阴性人数之和占所有进行诊断试验人数的比率。
越高越好
(a+d)/n ③Kappa 值
观察者对结果一致性的判断既可以用符合率表示,也可以用 Kappa 值来描述。与符合率相比,Kappa 值考虑了机 遇因素对一致性的影响并加以校正,从而提高了判断的有效性。
Kappa 值的计算公式如下:
察-致率(ot served agreement,p,)-⃞x100
实际一致率= Po – Pc;非机遇一致率= 1 – Pc
Kappa 值的取值范围在 -1 和 1 之间。
当 Kappa 值为正数且 Kappa 值越大,说明一致性 越好。
一般认为 Kappa 值≥ 0.75 为一致性极好;Kappa 为 0.4 ~0.75 为中、高度一致;Kappa 值≤ 0.40 时一致性差。
④影响试验可靠性的因素
1、试验方法的变异
2、观察者的变异
3、受试对象个体生物学变异 n 收益
①预测值
1、阳性预测值(PPV)
是指试验结果为阳性时真正患有目标疾病的人所占的比例。对于一项试验来说,阳性预测值越大越好。
2、阴性预测值(NPV)
是指试验结果为阴性时真正不患目标疾病的人所占的比例。阴性预测值也是越大越好。
②社会经济效益:成本效益分析、效果分析、效用分析
(九)各项指标之间的关系
l 灵敏度与特异度的关系
灵敏度与特异度是评价一项筛检或诊断试验真实性的两个基本指标,反映试验本身的特性,与患病率无关。但事实, 当诊断界值改变时,提高了灵敏度,则特异度下降;提高了特异度,则灵敏度下降。
l 灵敏度、特异度、疾病患病率与预测值的关系
1、灵敏度、特异度对预测值的影响
患病率相同时,灵敏度越高,阴性预测值越高,医生越有把握判断结果为阴性的受试者为非患者; 特异度越高,阳性预测值越高,医生越有把握判断结果为阳性的受试者为患者。
2、患病率对预测值的影响
当一项试验的灵敏度和特异度确定后,阳性预测值与患病率成正比,阴性预测值与患病率成反比。 当灵敏度与特异度一定时,疾病患病率降低则阳性预测值降低,阴性预测值升高;
当患病率一定时,试验灵敏度降低则特异度升高,阳性预测值升高,阴性预测值下降。
(十)提高筛检效率的方法
①优化试验方法
②选择患病率高的人群
③采用联合试验
1、并联实验
【平行试验】,即多项试验同时进行,只要有任何一项试验结果为阳性就判定最终结果为阳性,只有全部试验结果 均为阴性才判定最终结果为阴性。
特点:可以提高灵敏度,减少漏诊,使阴性预测值升高,但是会降低特异度,增加误诊,使阳性预测值下降。
2、串联试验
【系列试验】,是指依次顺序应用多项试验,只有全部试验结果均为阳性时才能判定最终结果为阳性,任何一项试 验结果为阴性就可判定最终结果为阴性。
特点:可以提高试验的特异度和阳性预测值,但是降低了试验的灵敏度,增加了漏诊。当目前使用的几种诊断方法 的特异度均较低时,可选用串联试验减少误诊。
思考题:
1.筛检的主要应用是?
2.如何评价筛检试验的效果?
3.开展筛检试验应注意哪些问题?
九、病因与因果推断
掌握:
1. 病因的概念,病因模型。
2. 病因的推断过程、判断标准。 熟悉:
病因逻辑推理方法。 了解:
流行病学病因研究过程,病因发展过程。
(1)病因的定义
Lilienfeld 概率病因学说:
能使人群发病概率升高的因素,就可认为是病因,其中某个或多个因素不存在时,人群疾病频率就会下降。
流行病学一般将病因称为危险因素,指能使疾病发生概率升高的因素,包括化学、物理、生物、精神心理及遗传等。
(2)病因的分类
l 作用性质分
①充分病因
是指有该病因存在,必定(概率为 100%)导致疾病发生,即一组必然导致疾病发生的最低限度的状态和事件。 这类病因在急性病中表现较为明显。
②必要病因
是指有相应疾病发生,以前必定有该病因存在,即引起某种疾病发生必须具备的条件,一旦该因素缺乏,疾病就 不会发生。这类病因在传染病、职业病、地方病中的表现尤为突出。
l 按病因是否充分或必要分类
①充分且必要病因——传统因果观;几乎不存在
②必要但不充分病因——传染病病原体;Vit 缺乏症的 Vit 不足
③充分但不必要病因——致死量的毒物;几乎也不存在
④不充分且不必要病因——吸烟——肺癌
l 病因作用方式分类
直接病因;间接病因
l 病因的来源分类
宿主因素;环境因素
(3)病因模型
概念:是用简洁的概念关系模式图来表达病因与疾病间的关系,提供因果关系的思维框架、涉及了各个方面因果关 系的路径。
l 三角模型(triangle model)
疾病的发生是宿主、环境、致病因子三要素共同作用的结果。主要用于传染病的研究 l 轮状模型(wheel model)
【车轮模型】
核心是宿主,其中的遗传物质有重要作用。外围的轮子表示环境(生物、理化、社会环境) 特别对于慢性非传染性疾病。
l 病因网模型(web of causation model)
①病因链:不同的致病因素与疾病间构成不同的连接方式;根据位置分为近端、中间、远端病因
②病因网:多个病因链交错连接起来就形成病因网 特点:1 、表达清晰具体、系统性强;
2 、可对病因做全面探索;
3 、提供因果关系的完整路径
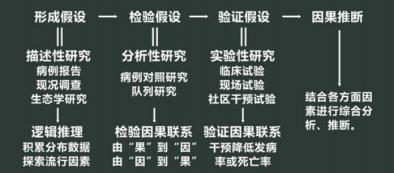
(4)因果研究一般过程
l 1 、病因假设的建立
方法:描述流行病学;研究内容:描述疾病三间分布
研究类型:横断面研究、纵向研究、生态学研究;eg:吸烟与肺癌
l 2 、病因假设的检验与验证
方法:分析流行病学、实验性研究
①病例对照研究 ②队列研究
目的:排除偶然关联,初步检验病因假设 目的:排除虚假、间接关联,深入检验病因假设
内容:病例组、对照组暴露的差异 内容:暴露组、非暴露组结局事件发生率的差异
eg: 肺癌患者与对照组人群吸烟状况的差异 eg: 吸烟与不吸烟者肺癌发病率差异
③实验性研究
目的:控制各种偏倚、混杂,最终证实因果关联
内容:治疗组、对照组疗效差异,治疗前后事件发生率的变化 eg:戒烟的干预实验
l 3 、因果关联推断
(五)因果推断的逻辑方法
①假设演绎法 推理形式:
1. 因为假设 H ,所以推出证据 E(演绎推理)。
2. 因为获得证据 E ,所以反推假设 H(归纳推理)。
假设演绎法的整个推论过程为:从假设演绎地推导出具体的证据,然后用观察或实验检验这个证据,如果证据
成立,则假设亦成立。 Eg:
提出假设 H :怀孕早期服用反应停是导致畸形儿的原因。 演绎地推出若干具体经验证据:
E1:畸形儿母亲服用反应停的比例高于正常儿童
E2:母亲服用反应停组畸形儿出生率高于母亲未服用组 E3:控制反应停的服用后,畸形儿的出生率下降
如果 E1 ,E2 ,E3 成立,则假设 H 亦获得相应强度的归纳支持。
②Mill 准则
1. 求同法 是指在发生相同事件的不同群体之间寻找共同点。
2. 求异法 是指在事件发生的不同情况的不同群体之间寻找不同点。
3. 共变法 当有关(暴露)因素不是二分类的(有或无),而是等级或定量的,并与事件结局效应成量变关系(剂 量-反应关系),则该因素很可能是该病的病因。
4. 剩余法 是指某病发生是由多种因素所致时,把其中已确认有因果联系的部分减去,那么剩余部分必有因果关系。
5. 类推法 当一种病因未明疾病的分布与另一种病因已清楚的疾病的分布相似时,则把该病病因推断为不明原因疾 病的可能病因。
(六)疾病与因素间关联的种类
①因果关联:是指一定的原因产生一定的结果。
②虚假关联
【人为关联】,是指本来两事件间不存在统计学上的关联,但在研究过程中,由于没考虑到设立对照组、对照 组的选择不当、观察指标不客观、样本的代表性不强或其他偏倚存在时,可造成研究因素与疾病间的虚假关联。
来源:选择偏倚、信息偏倚、混杂偏倚
③间接关联
【继发关联】,通常指由混杂偏倚所致的关联。
是指本来两事件不存在因果关联,但由于两事件的发生都与另外一种因素有关,结果两事件间出现了统计学上的联 系,即产生了混杂。
(七)因果关联的推断标准【9 条】
l 关联的时间顺序
1. 因果关联中,有因才有果,先因后果:从“因”→“果”:暴露因素 X→疾病 Y ,则 X 必须发生于 Y 之前
2. 在确定前因后果的时间顺序上,实验研究、前瞻性研究中容易判断,但病例对照研究或横断面研究中则常常 难以判断。实验和队列研究>病例对照和生态学研究>横断面研究
3. 慢性病需注意 X 与 Y 的时间间隔
石棉与肺癌:石棉暴露到发生肺癌至少要 15-20 年,而暴露于石棉环境中 3 年就发生了肺癌,则显然不能归于石棉。
l 关联的强度
关联强度主要指标以相对危险度(RR)或比值比(OR)表示;在设计和分析都正确的前提下,如果 RR≥3 ,那 么两事件间很可能存在因果关联。
l 剂量反应关系
关联强度的一种特殊表现形式,随着某因素暴露剂量的增加,人群中发生某疾病的频率随之增加、因果联系的 强度增大,则认为该因素与该疾病间存在剂量反应关系。
l 关联的可重复性
l 实验证据:用更可靠的实验性研究
l 关联的生物学合理性
l 关联的特异性
l 关联的分布一致性:三间分布
l 关联的相似性
(八)因果关联的综合判断
1 、存在关联(包括剂量效应关系) 以及关联的时间顺序是判断因果关系的必要条件和特异条件;
2 、关联的可重复性是重要的依据
3 、关联的特异性、关联的生物学合理性和实验证据作为参考条件
十、偏倚和控制
掌握:偏倚的定义、分类;
选择偏倚、信息偏倚和混杂偏倚的定义、常见类型
熟悉:选择偏倚、信息偏倚和混杂偏倚的控制 了解:混杂偏倚大小及方向的判断
(一)偏倚的概念与分类
概念:是指在流行病学研究的设计、实施、资料分析阶段由于研究方法的缺陷或错误造成对暴露和疾病关系的错误 估计而产生的系统误差和结果解释及推论中的片面性。
偏倚是一种系统误差,有方向性
分类:选择(设计)、信息(实施)、混杂(设计和资料分析)
(二)选择偏倚及其控制
发生在研究对象的选择过程中,抽样中(病例对照和现况调查常见) l 分类
①入院率偏倚:【伯克森偏倚】
②检出症候偏倚
是指某因素与某疾病虽无关联,但因暴露于该因素可引发该病的某些症状或体征,使患者及早就医,以致该病 在该人群中的检出率高于一般人群,从而得出该因素与该疾病相关联的错误结论, 由此而产生的系统误差。
③现患病例—新发病例:【奈曼偏倚】
是指以现患病例为对象进行研究和以新发病例为对象进行研究时相比,因研究对象的特征差异所致的系统误差。
④无应答偏倚:失访
⑤易感性偏倚(健康工人效应)
是指在观察性研究中,由于样本人群与总体人群之间或对比组人群之间对所研究疾病的易感性不同而引起的偏倚。
l 如何控制:
①研究者对整个研究过程可能出现的各种选择偏倚应有充分的了解、掌握
②严格掌握研究对象的纳入与排除标准,采用或制定明确、统一与公认的诊断标准,尽可能选择各级医院的早期病 人为研究对象。
③采取措施提高应答率
④采用多种对照
l 具体研究方法:
1)横断面调查:采用随机抽样,并保证一定的样本含量,以增强样本的代表性,必要时可采用分层随机抽样的方 法,尽量提高应答率。
2)病例对照研究:最好用人群中全部新发病或新发病的随机样本;对照能代表产生病例的人群。若难以做到,则 在多个医院选择病例,同时选择医院与社区对照,并尽可能选用新病例,不用老弱对象。
3)队列研究:尽量减少失访。
4)现场实验:随机抽样选择研究对象,并进行随机分组。
5)在诊断疗效与预后研究中,尽可能扩大选择病例的范围,如多中心临床研究,并包括主要特征的各类各种病人。
(三)信息偏倚及其控制
【观察偏倚】或【错误分类偏倚】,
是指在收集整理信息过程中由于测量暴露与结局的方法(工具)有缺陷,使收集到的信息不准确(即不完全 真实),造成对研究对象的归类错误。
信息偏倚既可以来自于研究对象和调查者,也可以来自于测量的设备、仪器和方法等。 l 分类
①回忆偏倚:是指研究对象不真实的回忆所导致的误差。多见于病例对照研究。
②报告偏倚:研究对象因某种原因有意的夸大或缩小某些研究信息而导致的系统误差。
③暴露怀疑偏倚:指研究者若事先了解研究对象的患病情况或某结局,可能会对其采取与对照组不可比的方法探寻 认为与该结局有关的暴露因素。
④诊断怀疑偏倚:是指由于研究者更想得到暴露于某因素者易发生某疾病的结论,故而在诊断疾病时对暴露组采取 了比非暴露组更认真的方法和态度,致使暴露者更易做出某疾病诊断的情况,而产生的系统误差。
多见于临床试验和队列研究。
⑤测量偏倚:是指研究者对研究所需数据进行测量时产生的系统误差。
⑥发表偏倚:是指阳性结果的研究比阴性结果的研究更易得到发表,使人们从公开发表的刊物上获得的信息与真实 情况不符而产生的系统误差。
l 如何控制
①研究设计阶段
统一方法、统一标准;采用客观指标
②资料收集阶段
盲法收集信息;调查技术的应用 ③资料分析阶段
错分分析方法,对结果效应估计值予以矫正。
(四)混杂偏倚及其控制
研究因素与疾病之间的关联程度受到其他因素的歪曲或干扰而产生的系统误差。导致混杂产生的因素称为混杂 因素。混杂因素的特点:
(1)是疾病的危险因素;
(2)与研究因素有关;
(3)不是研究因素与研究疾病因果链上的中间病因。
l 混杂偏倚的控制
随机化、限制、匹配、多层分析、多因素分析
总复习
1 、如何选择研究方法?
l 治疗 – RCT
l 预后 – 队列(RCT)
l 风险 – 队列 (病例对照)
l 频率/患病率/诊断方法的比较 –现况研究
2 、假如想研究以下医学科研问题,可以采用什么研究方法?各有什么利弊? 使用电脑工作是否会增加流产几率?风险/危害——队列/病例对照
婴幼儿接种疫苗是不是自闭症的危险因素?风险/危害——病例对照(队列) 服用维生素能否降低中风几率?治疗——随机对照试验
糖化血红蛋白是否比糖耐量检查(OGTT)更好地诊断糖尿病?诊断——横截面研究 有多少人患有糖尿病但是尚未诊断? 患病率——横截面研究
3、
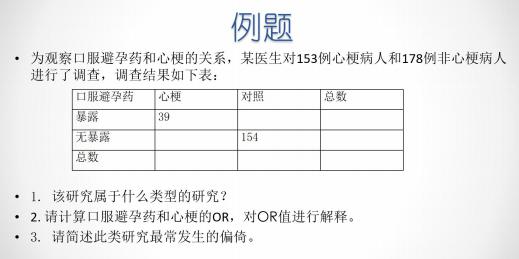
4 、少女阴道腺癌是一种罕见病,Herbst 医生采用了一种流行病学研究方法来研究,得出结论,这些病人的母亲在 孕期使用雌激素与该病相关。
1.该研究属于什么类型的研究? 2.请描述研究设计原理。
5 、某研究调查了两个城市的哮喘的流行情况,研究对象是 10-15 岁青少年。A 城市调查了 3300 人,其中 300 人报 告诊断为哮喘;B 城市调查了 2700 人,其中400 人报告诊断为哮喘.
1.该研究属于什么类型的研究? 2.计算两个城市的患病率。
3.请从流行病学角度描述 B 城市患病率较高的可能原因。
6 、对 7000 人随访 5 年,其中 3000 人服用维生素补充剂,4000 人没有服用。5 年后,在服用维生素补充剂的人当 中,有 57 人患有癌症,而在没有服用的人当中,43 人患有癌症。
1.该研究属于什么类型的研究?
2.请计算该种研究类型的关联强度指标(RR 或者 OR?) 3.请解释该关联强度指标的含义。
2025-05-12-1024x1024.png)